By Scott Eichelberger Ph.D., Energy Assessment Analyst and Application & Product Manager
Bingqing Peng, Data Scientist
& Matthew Hendrickson, Head of Energy Operations
Vaisala
A tremendous amount has changed in wind-energy technology over the past decade, including the size and capacity of wind turbines and the business models used to site and finance them. The methods for calculating a project’s annual energy yield have also advanced over the last 10 years. Previously, an industry-wide underperformance of 10% or more was typical. So, wind-resource analysts were forced to do a deeper evaluation of the way project risk was understood and quantified in energy estimates to learn why and how to improve wind performance predictions.
Following significant validation work across the industry, many consulting firms have demonstrated the calibration of their energy estimation methods compared to actual production data. However, the results showed that most methods performed well — on average. To this day, considerable project-to-project variability in terms of uncertainty remains in validation studies, providing ample incentive to continue to advance wind-resource assessment methods.
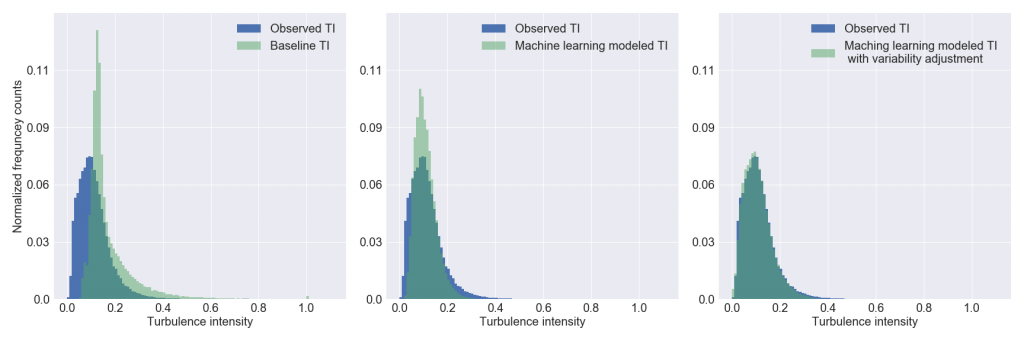
The histogram of TI values are for the observational data, as well as for each of the three models: Baseline, Machine Learning, and Machine Learn with Variability Adjustment. Notice the good agreement in the third chart. The histograms represent the aggregated data across all 29 test sites.
Wind-resource assessments have a direct impact on which projects are financed and constructed and which ones are not. A reduction in uncertainty also improves financial terms for developers. In addition, when wind projects perform closer to expectations, it strengthens the trust between consultants, developers, the financial community, policymakers, and the general public.
While the wind industry continues to gain experience, today’s competitive environment makes it imperative to take advantage of the latest scientific advances, which may increase accuracy, performance, and improve the cost-effectiveness of wind farm development by reducing the scope and duration of measurement campaigns. With tighter financial markets and a push toward more challenging project locations, it is important to ensure that the employed method of wind-resource assessment uses the most sophisticated technology available for siting, optimizing, and financing wind farms.
The three pillars
The goal of a wind assessment is to accurately estimate the wind resource and energy output of each wind turbine for a project site over its lifetime, which is typically for 20 to 30 years or more. However, assessments often start with short-term measurement records from a few different points at the project site. So, it is necessary to find a way to translate these measurement records into reliable estimates of wind behavior and power generation at each turbine location over the lifetime of a wind farm.
This is far from a simple task, particularly because other challenges arise due to permitting costs, aggressive timelines, and tight budgets. Furthermore, accurate wind-resource assessment requires years of expertise and advanced tools in weather and data science.
To create a cost-effective, reliable wind project assessment, while adhering to the market demands of speed and accuracy, a three-tiered approach has proven ideal. It entails use of:
- Sophisticated physical models
- Onsite observational data
- Machine-learning algorithms which fuse physical models with observational data.
Currently, the most advanced computer or physical model available (which uses physics’ based rules to explain and predict the physical atmosphere) is the Weather Research & Forecasting (WRF) model. WRF is an open-sourced numerical weather-prediction (NWP) model that has been collaboratively developed across many institutions, including the National Center for Atmospheric Research, the National Centers for Environmental Prediction, and the Forecast Systems Laboratory.
WRF plays a key role in the three-tiered approach because it calculates the fine-scale spatial structure of wind resources across a project site (i.e. turbine-to-turbine wind speed variations), and the long-term climate variability of the wind resource (i.e. month-to-month and year-to-year wind speed variations). Weather and climate are extremely complex to predict and understand. The WRF model’s ability to capture a larger percentage of the physical and dynamical processes driving the time-varying atmospheric variability leads to more accurate results, and it is currently the most technically complete model.
Onsite measurements are a key investment in a wind farm’s resource assessment because the data provides a “ground-truth” understanding of conditions at the site. In fact, in an ideal world, observations would be collected at every potential turbine location. However, this is impractical and far too time and cost-prohibitive, so advanced models such as WRF are used instead. Observational data are also employed to verify the physical model results, with the aim of reducing overall uncertainty of the wind-resource assessment. This step is necessary because even the most advanced physical model provides imperfect data, so its results are corrected using observations.
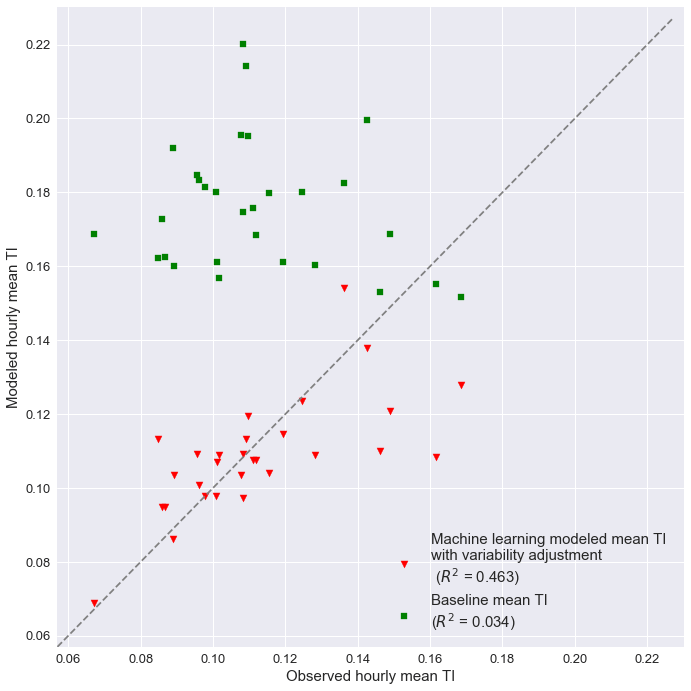
The scatter plot compares observed and predicted TI values at each of 29 test sites. The green squares denote the Baseline model, and the red triangles represent the Machine Learning with Variability Adjustment model. Typically, dots matching up with the trend line are more favorable (the red dots show better agreement then the green dots from the baseline case).
Machine-learning algorithms are the preferred approach for reducing model errors and improving results. Machine learning is the use of artificial intelligence that provides a system the ability to learn and adapt through experience, without being explicitly programmed. The algorithms are able to identify patterns in large existing data sets, and then these patterns can be applied to new data sets.
Machine learning has a wide range of applications including security, online search, financial trading, facial recognition, and marketing.
For wind applications, machine-learning algorithms analyze the rich data sets from the WRF model and compare them to onsite observations. The algorithms “learn” how the physical model results can be adjusted or corrected to better match the observed data. The corrective algorithms use many different predictor fields from the model, such as temperature, pressure gradients, shear, and stability. Once the time-varying corrective algorithms are developed, corrections can occur for places and periods without direct observations, such as over the past several decades at all turbine locations.
The pitfalls of short cuts
The combination of all three pillars delivers the highest quality wind-resource assessments and helps keep uncertainty as low as possible. If one pillar is missing, the assessment is degraded and the project development costs of a wind farm will likely increase.
For example, if onsite observational data is of poor quality, additional pressure is put on the physical model and machine-learning algorithms to accurately capture wind variability and translate this information into energy estimates. Without the ability to compare the results against reliable measurement records, a developer must rely on the physical model and machine-learning algorithms and hope the system has the capability to accurately simulate all aspects of a site’s meteorology. A sophisticated physical model, such as WRF, offers greater reliability, however, the analysis uncertainty increases without onsite verification.
Similarly, employing a less sophisticated physical model places stress on the machine-learning algorithms and the observational met campaign.
The Wind Atlas Analysis and Application Program (WAsP) and Computational Fluid Dynamics (CFD) are two examples of other physical models that are used in the industry for wind-resource assessment. However, both approaches simplify the equations of motion in the atmosphere and only provide steady-state results. These simplifications allow for faster processing, but at the expense of a comprehensive analysis of the weather variability at a project.
When such models are used for an assessment, the machine-learning algorithms provide diminished value because the data fails to accurately capture the complex flow patterns of the atmosphere. To help keep uncertainty in check, a more rigorous met campaign with additional measurement sites is needed, which can significantly increase project development costs.
Without machine-learning algorithms, it is necessary to use less advanced methods to correct the model data using the observations (e.g. a simple bias removal via algebraic methods). Non-learning methods also fail to take advantage of additional weather data from WRF model simulation. By omitting this additional weather data, non-learning methods tend to be less efficient and open the possibility for increased errors. These errors may be mitigated with additional measurement sites, but that also increases development costs.
When all three components are used together in an assessment, it is possible to minimize development costs by reducing the scope and duration of a wind-measurement campaign. This is partly because a physical model (merged with onsite observational data via machine learning algorithms) will provide increased accuracy when making predictions farther away from measurement sites. This allows developers to use a sparser met campaign (one with fewer measurement points or equipment, such as met towers or remote sensors) without sacrificing the quality or uncertainty of the wind-resource assessment. Depending on the measurement equipment, reducing even a single measurement location may save a developer hundreds of thousands of dollars.
The three-tiered pillar approach can be used whenever the objective is to better predict wind behavior and variability and understand how this translates to power generation. For example, these same principles can be employed in a range of applications beyond pre-construction wind resource assessment, including short-term operational wind forecasting and long-term seasonal forecasting, which are critical for energy integration, plant operations, and budget planning.
As the wind industry continues to mature in its approach to quantifying project risk, techniques founded in weather and data science will gain additional traction and lead the way to improved accuracy and reduced uncertainty.
Machine learning in action
In a recent case study, Vaisala used a combination of NWP models and observations to develop a machine-learning algorithm to more accurately estimate turbulence intensity (TI). TI is an important factor in wind-resource assessment for site suitability, turbine selection, and wake and turbine performance losses. However, it typically can only be measured at point locations via met towers, or estimated using compute-intensive models.
Mesoscale NWP models, such as WRF, can estimate TI for reasonable computational costs, but can exhibit situational-dependent biases.
To resolve these limitations, Vaisala researchers developed a machine-learning algorithm that is applicable in any geographic location and uses much of the WRF model’s output variables as predictors to produce an improved TI field.
Gradient-boosting regression models produce a first estimate of TI, then variance adjustment is used to better match the observed TI distribution from a large existing training database of diverse, globally distributed met towers. The machine-learning-based TI model is compared to a simple TI model based on physical principles rather than empirical training. The gradient-boosting regression model shows a significant advantage over the baseline model using an independent test set of diverse, globally distributed met towers (as shown in the above tables).
Filed Under: News



